知识库搜索参数
language
知识库搜索参数
知识库搜索原理
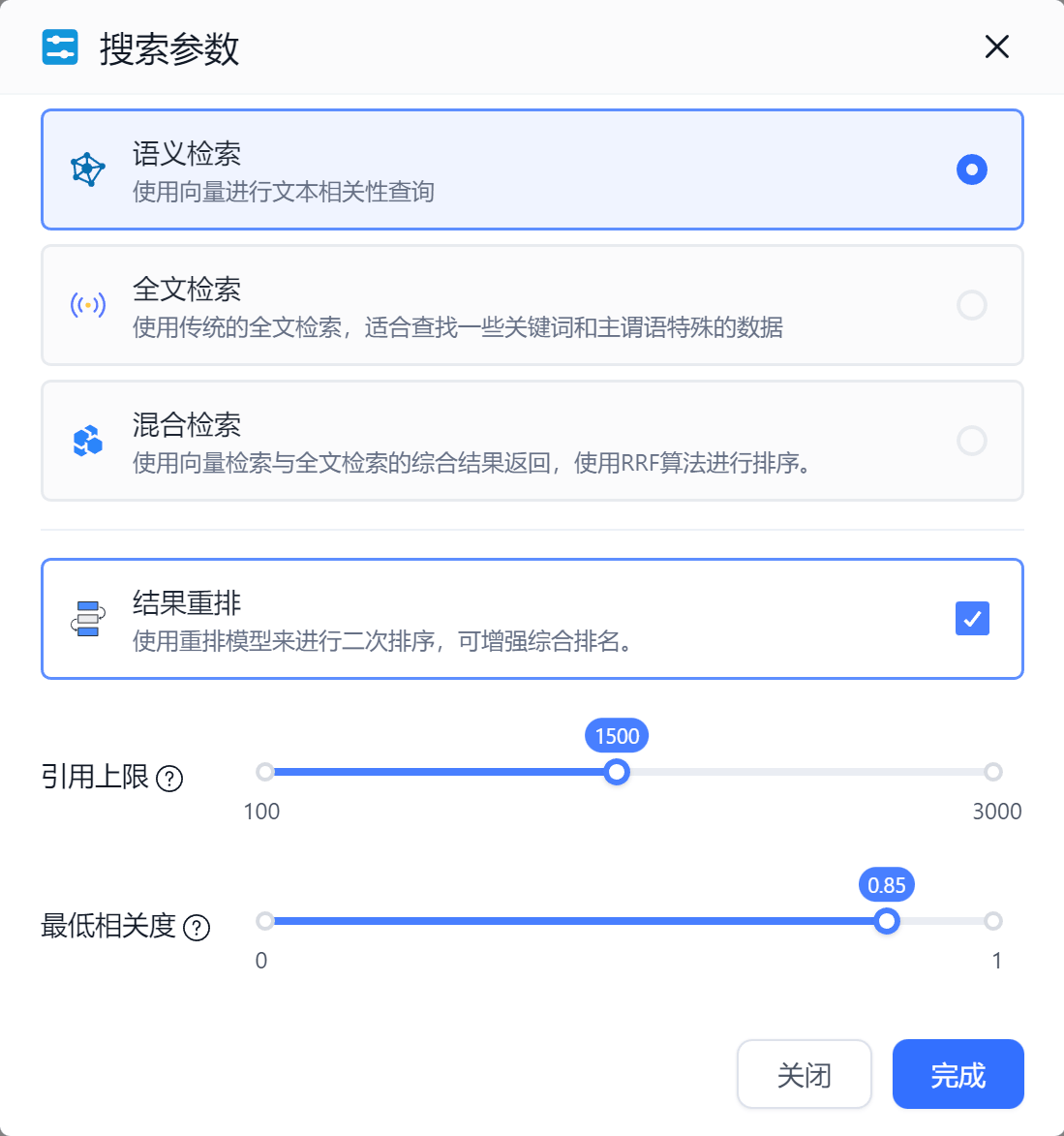
在知识库搜索的方式上,FastGPT提供了三种方式,分别为“语义检索”“增强语义检索”“混合检索”。
搜索模式
语义检索
语义检索是通过向量距离,计算用户问题与知识库内容的距离,从而得出“相似度”,当然这并不是语文上的相似度,而是数学上的。
优点:
- 相近语义理解
- 跨多语言理解(例如输入中文问题匹配英文知识点)
- 多模态理解(文本,图片,音视频等)
缺点:
- 依赖模型训练效果
- 精度不稳定
- 受关键词和句子完整度影响
全文检索
才用传统的全文检索方式。适合查找关键的主谓语等。
混合检索
同时使用向量检索和全文检索,并通过 RRF 公式进行两个搜索结果合并,一般情况下搜索结果会更加丰富准确。
由于混合检索后的查找范围很大,并且无法直接进行相似度过滤,通常需要进行利用重排模型进行一次结果重新排序,并利用重排的得分进行过滤。
结果重排
利用ReRank模型对搜索结果进行重排,绝大多数情况下,可以有效提高搜索结果的准确率。不过,重排模型与问题的完整度(主谓语齐全)有一些关系,通常会先走问题补全后再进行搜索-重排。重排后可以得到一个0-1的得分,代表着搜索内容与问题的相关度,该分数通常比向量的得分更加精确,可以根据得分进行过滤。
FastGPT 会使用 RRF 对重排结果、向量搜索结果、全文检索结果进行合并,得到最终的搜索结果。
引用上限
每次搜索最多引用n个tokens的内容。
之所以不采用top k,是发现在混合知识库(问答库、文档库)时,不同chunk的长度差距很大,会导致top k的结果不稳定,因此采用了tokens的方式进行引用上限的控制。
最低相关度
一个0-1的数值,会过滤掉一些低相关度的搜索结果。
该值仅在语义检索或使用结果重排时生效。