接入 ChatGLM2-m3e 模型
model_training
接入 ChatGLM2-m3e 模型
将 FastGPT 接入私有化模型 ChatGLM2和m3e-large
前言
FastGPT 默认使用了 OpenAI 的 LLM 模型和向量模型,如果想要私有化部署的话,可以使用 ChatGLM2 和 m3e-large 模型。以下是由用户@不做了睡大觉 提供的接入方法。该镜像直接集成了 M3E-Large 和 ChatGLM2-6B 模型,可以直接使用。
部署镜像
- 镜像名:
stawky/chatglm2-m3e:latest - 国内镜像名:
registry.cn-hangzhou.aliyuncs.com/fastgpt_docker/chatglm2-m3e:latest - 端口号: 6006
# 设置安全凭证(即oneapi中的渠道密钥)
默认值:sk-aaabbbcccdddeeefffggghhhiiijjjkkk
也可以通过环境变量引入:sk-key。有关docker环境变量引入的方法请自寻教程,此处不再赘述。
接入 One API
为 chatglm2 和 m3e-large 各添加一个渠道,参数如下:
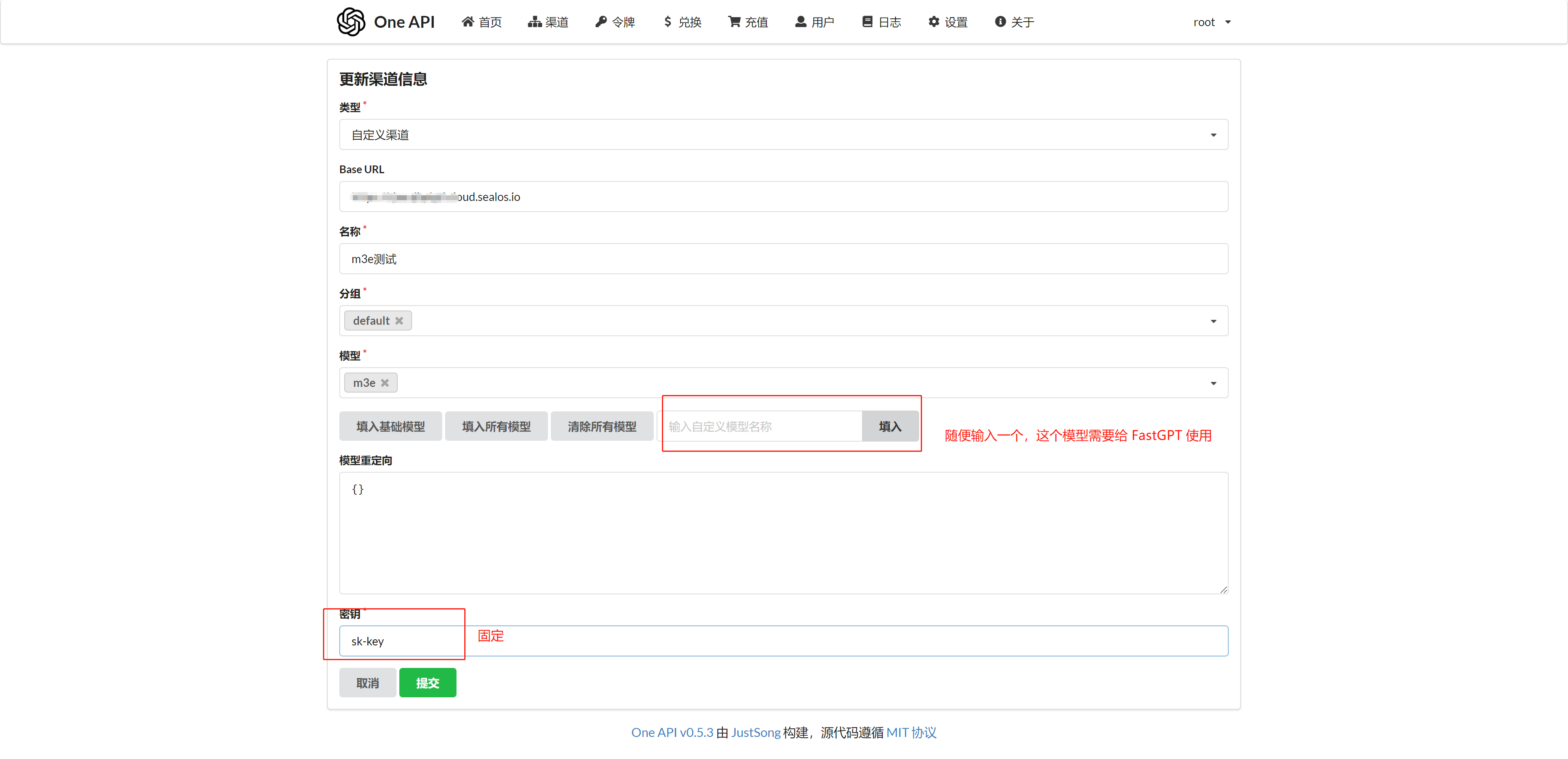
这里我填入 m3e 作为向量模型,chatglm2 作为语言模型
测试
curl 例子:
curl --location --request POST 'https://domain/v1/embeddings' \
--header 'Authorization: Bearer sk-aaabbbcccdddeeefffggghhhiiijjjkkk' \
--header 'Content-Type: application/json' \
--data-raw '{
"model": "m3e",
"input": ["laf是什么"]
}'
curl --location --request POST 'https://domain/v1/chat/completions' \
--header 'Authorization: Bearer sk-aaabbbcccdddeeefffggghhhiiijjjkkk' \
--header 'Content-Type: application/json' \
--data-raw '{
"model": "chatglm2",
"messages": [{"role": "user", "content": "Hello!"}]
}'
Authorization 为 sk-aaabbbcccdddeeefffggghhhiiijjjkkk。model 为刚刚在 One API 填写的自定义模型。
接入 FastGPT
修改 config.json 配置文件,在 ChatModels 中加入 chatglm2, 在 VectorModels 中加入 M3E 模型:
"ChatModels": [
//其他对话模型
{
"model": "chatglm2",
"name": "chatglm2",
"maxToken": 8000,
"price": 0,
"quoteMaxToken": 4000,
"maxTemperature": 1.2,
"defaultSystemChatPrompt": ""
}
],
"VectorModels": [
{
"model": "text-embedding-ada-002",
"name": "Embedding-2",
"price": 0.2,
"defaultToken": 500,
"maxToken": 3000
},
{
"model": "m3e",
"name": "M3E(测试使用)",
"price": 0.1,
"defaultToken": 500,
"maxToken": 1800
}
],
测试使用
M3E 模型的使用方法如下:
创建知识库时候选择 M3E 模型。
注意,一旦选择后,知识库将无法修改向量模型。
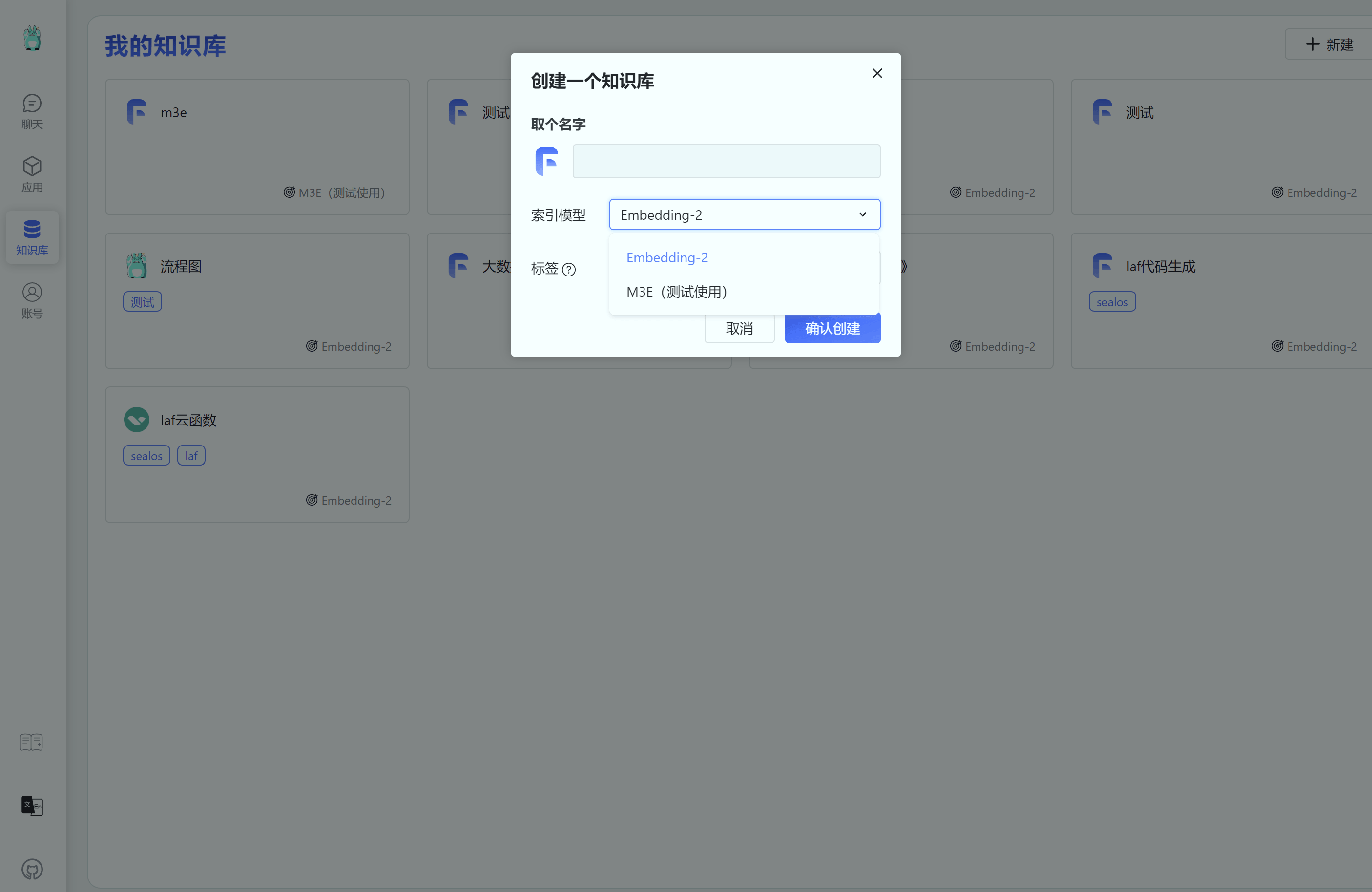
导入数据
搜索测试
应用绑定知识库
注意,应用只能绑定同一个向量模型的知识库,不能跨模型绑定。并且,需要注意调整相似度,不同向量模型的相似度(距离)会有所区别,需要自行测试实验。

chatglm2 模型的使用方法如下: 模型选择 chatglm2 即可